
Il y a deux mois, alité par la grippe, j’ai eu envie de jouer un peu avec les robots qui pourrissent le fonctionnement de mes serveurs, peut être que certains confrères y verront un causalité à l’outil :). Pour mémoire, je gère une petite 50aine de serveurs, pour mon compte ou celui de clients pour lesquels je fais l’admin sys.
Gentils robots / Méchants robots
Dans un article récent, il était annoncé que 70% du trafic d’un site était généré par des robots, dont la moitié serait des gentils robots. La vérité est bien différente, car la plupart de ses robots de vous rendent rien des ressources qu’ils vous pompent et des dysfonctionnements qu’ils provoquent. A part Googlebot, difficile de justifier les autres, même bingbot laisse largement à désirer tant il peut s’avérer gourmand sur des sites qui n’ont rien demandés et des serveurs dimensionnés pour de vrais clients et non un robot qui demandent 10 pages par seconde (particulièrement criant sur de petits virtuels avec un site prestashop aux multiples produits). L’interpretation du fichier robots.txt étant relativement aléatoire et les risques importants pour le référencement de votre site dans les moteurs présents ou futurs, il n’existe aucun moyen de bloquer sereinement tous les robots, sauf ceux qui nous intéressent. La bonne méthode serait l’opt-in de nos sites dans ces services mais signerait la mort de tous les outils payants offrants des services de reporting divers et avariés sur les sites, domaines et leurs contenus.
Les outils de suivis de liens
Parmi les robots, on trouve des services qui se sont spécialisés dans le crawl d’internet pour récupérer les liens entre les sites et vendre à prix d’or le résultat de leur indexation. Il y a 2 utilisations principales à ces outils
- Suivre les liens qui pointent vers votre site
- Suivre les liens qui pointent vers le site d’un concurrent pour en trouver ses bonnes idées
Dans le premier cas, il y a déjà les outils de suivis fournis par les moteurs de recherche, ils ont le lourd défaut d’être particulièrement peu à jour et souffrent d’une grosse inertie dans les résultats fournis. Mais il n’y a aucune garanti que le rapport fournit par l’outil tiers rende fidèlement l’image que le moteur peut avoir de votre site, ce sont deux systèmes complètement décorellés et étrangers. Tous les utilisateurs d’outils extrêmes comme Xrumer ou SeNuke savent bien qu’une page satellite orpheline ne leur apportera aucune aide pour leur positionnement, elle sera très vite désindexée du moteur et non pris en compte pourtant la plupart des outils de linking vous le rapporteront.
Dans le deuxième cas, est-il bien nécessaire de compléter ? Vous travaillez pour votre site, et les leechers se régalent pour 50€ / mois et peuvent mettre à profit tout le temps que vous avez passé en R&D à compléter votre travail.
Cloaking
what you see is not what others get
J’ai donc poussé un peu le concept, et développé un outil, maitrisé et optimisé qui va proposer aux robots de ces services de multiples pages optimisées pour remplir les pages de rapports des requêtes les plus populaires. Pour éviter qu’il n’y ait des effets de bords, le contenu des sites est cloaké de sorte qu’aucun visiteur non ciblé ne puisse accéder à ce contenu ( c’est sans doute la partie qui m’a demandée le plus d’efforts, être absolument à 100% sûr que je ne causerais aucune perte de trafic indirectement )
On en revient donc au commentaire du premier point ci dessus, le contenu des bases des outils de rapports de linking est désormais complètement décorellé de la réalité
Seofall en action
Le résultat est que les vrais liens sont masqués de la partie publique, qui elle, ne présente plus que des liens provenant de contenu sans intérêt. Et ce sera largement le cas prochainement dans la partie payante de ces « services » également.
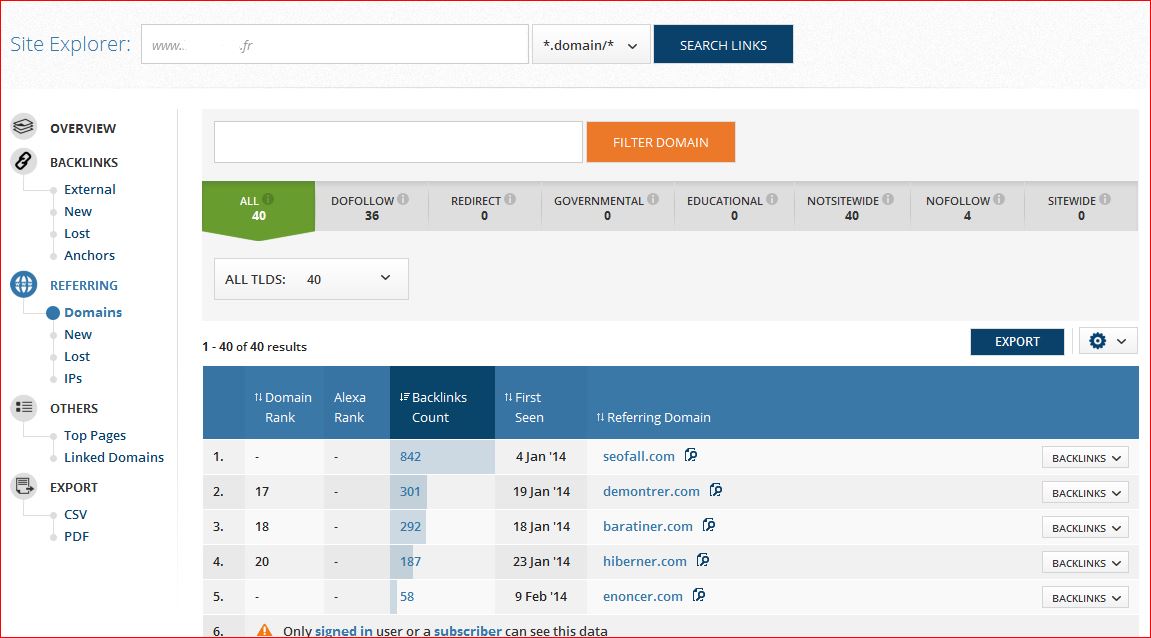
Tous les domaines ci-dessus sont les miens, y compris ceux cachés, mais si les noms visibles sont facilement identifiables, les autres resteront discrets pour une utilisation future, je ne tiens pas à les sacrifier sur la place publique.
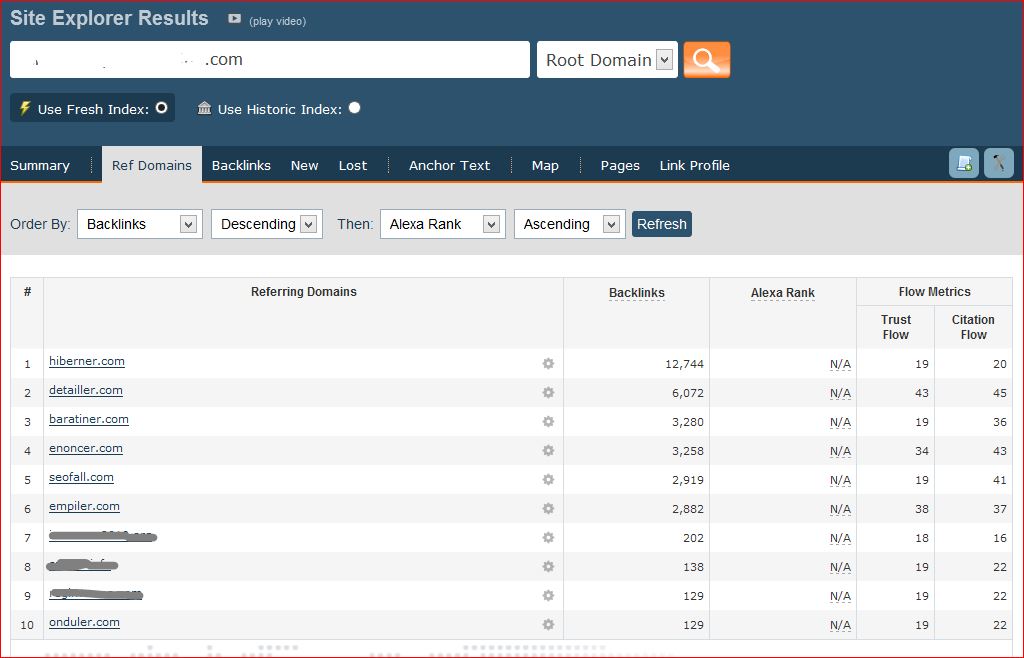
je n’ai pas vraiment chercher à cacher mon travail, le whois de tous les domaines étant public jusqu’à la fin du test ( voir fin de l’article ) et pour les visiteurs (ie: les non robots ciblés) je faisais une redirection 302 vers mon propre site.
La parano NSEO créée par Google
J’ai été contacté depuis 2 mois pour connaitre la réalité de ce qui était visible dans les fameux outils, voici une réponse synthétique 🙂
Oui, j’ai généré des pages dans le seul but de comprendre le fonctionnement des robots et systèmes de rapports de liens sur internet, et les rapports fournis par ces outils s’en sont trouvés faussés, tout comme la charge des sites que j’administre est faussé par les dysfonctionnements provoqués par leur robots, et mon activité personnelle est perturbée par les dérangements que j’ai subis, et continuerais de subire, pour réparer leur activité.
Non, il n’y a jamais eu aucun impact sur le référencement de votre site et ce test ne peut pas être mis en cause ni dans les changements de positions qu’un moteur lui a fait subire, ni dans l’évolution de votre trafic.
Les vrais experts en référencement, voire ceux qui ont sur rester humble, qui m’ont contacté l’avaient bien compris et m’ont simplement demandé « à quoi je jouais » ou « à comprendre », ce que j’ai fais avec plaisir, j’avais d’ailleurs prévu dès le départ une white liste pour intégrer les domaines qui ne devaient être affectés (vous l’aurez compris, aucun de mes sites n’a jamais été whitelistés). Les autres dont le comportement étaient totalement inadapté ont pu mariné, voire progresser un peu une fois qu’en leur machant un peu le travail, ils ont compris la supercherie. La prochaine fois, tournez-vous vers votre fournisseur qui bondit d’un paradis fiscal à l’autre en fonction de la législation bancaire et demandez lui d’être plus efficace, le contenu généré a un très très au degré de duplication et un très faible volume de liens externes.
La suite
Mes demi excuses à mes confrères qui ont perdu un peu de temps dans ma petite expérience, mais s’ils ont stressé et cherché, j’espère que cela leur aura permis de prendre un peu de recul face aux outils qu’ils payent très cher et dont les rapports rendus ne sont finalement que ce que les webmasters finiront par bien vouloir leur laisser. Comme je l’ai déjà dis, je ne mettais pas vraiment caché au début, et si j’avais voulu le faire ou si je devais tomber si bas que j’en viendrais à faire du NSeo, faites moi confiance pour être impossible à démasquer et laisser une piste aussi énorme qu’un reverse DNS et mon numéro de téléphone.
L’expérience est globalement concluante et m’a permis sur un petit panel de mots clefs et d’expressions de valider l’usage des outils vendus, la voracité des robots d’indexation de ces outils et leur absence totale d’intelligence au delà de la recherche de liens.
La base de données servant à « créer » les sites a été nettoyée depuis déjà quelques jours (en même temps que le whois légèrement masqué, si j’avais vraiment pas voulu être trouvé, ce n’était pas bien compliqué de le faire vraiment, hébergé en France actuellement. Alors Nseo, franchement ? sérieux ? ) et si vos stats de liens se sont trouvées quelque peu chahutées, tout devrait revenir à la normal plus ou moins rapidement selon l’efficacité et/ou l’inertie de votre cher outil souscrit.
A l’inverse, j’ai passé la vitesse supérieure concernant le nombre de sites pour nourrir les outils concernés, et si vous souhaitez noyer votre profil public de liens qui vous servent vraiment à ranker, vous savez ou vous adresser 😉
PS: si le modèle d’indexation devenait l’opt-in, cette solution serait de facto désuète, et j’en serais ravi 🙂
PPS: ce billet est susceptible de s’auto-détruire pour les besoins du service
PPPS: les réponses des outils pour disparaitre de leur base proprement… good luck
"you are welcome to request our bots do not visit your website […]But links to your website,will still be indexed by us" : @MajesticSEO
— Nicolas (@Salemioche) February 24, 2014
"Block via robots.txt is the only way of preventing AhrefsBot from crawling your domains.We do not delete anything from our base" : @ahrefs
— Nicolas (@Salemioche) February 24, 2014
He bien, on sait à quoi tu utilises tes domaines inexploités. Cela m’amène plusieurs questions :
Est-ce qu’un disallow dans le robots.txt n’aurait pas été suffisant ?
N’as-tu pas peur de griller des domaines avec cette opération un peu visible ?
Le robots.txt implique de faire confiance aux tiers…
Je n’ai utilisé que des domaines déjà cramés et/ou inutilisés que je ne souhaitais pas renouveller (à part seofall.com acheté pour l’occasion fin décembre), c’est le plus beau de l’histoire, on fait un peu ce que l’on veut
Tu m’étonneras toujours belle démonstration.
« s’ils ont stressé et cherché, j’espère que cela leur aura permis de prendre un peu de recul face aux outils qu’ils payent très cher et dont les rapports rendus ne sont finalement que ce que les webmasters finiront par bien vouloir leur laisser. »
+1000
Tu as mis Paul dans l’embarras pendant 2 secondes quand il a voulu montrer un exemple de site sans bl au salon de l’e-tourisme à St Raphael et euh, mince… Mais non c’est encore une connerie d’un pote.
Super travail Nicolas !
Sacré démonstration sur la possibilité de fausser le trafic et les données… on peut y voir pas mal de possibilités 😉
Ca me fait penser à l’intervention de Yakamo sur le bh analytics lors du premier barcamp bh à Toulouse, en 2011 déjà
Il n’y a aucun traffic de faussé et généré, ce ne sont que les données d’outils qui ne correspondent plus à l’usage pour lequel elles sont destinées 🙂
Salut,
Est-ce qu’un SetEnvIfNoCase (sur .htaccess) ciblant les user-agent en mod_security pourrait éviter ça ? Ou bien tous les crawlers font le forcing ?
probablement, mais c’est la plaie à maintenir
J’avoue que tu m’as donné du fil à retordre avec ton truc 😉 Quand j’ai découvert seofall, enoncer, barratiner et cie, j’ai fouillé jusqu’à chercher une alternative à webarchive.org (cf ce tweet : https://twitter.com/htitipidotcom/status/433236116956012544 ) et j’ai finalement trouvé un « screenshot » de seofall (plus disponible et pas sauvegardé) avec screenshots.com. C’est bien maigre ^^
le screenshot devait etre celui de l’ancien proprio, je n’ai jamais rien mis en ligne d’accessible
L’idée est génial pour attirer l’attention, dommage pour les culs bénis qui s’en sont offusqués! :p
merci 😉
Chapeau l’artiste, je pense que tout comme moi, pas mal de monde a cherché ce qu’il en retournait et quel en était l’objectif. C’est fort.
Salut Nico,
J’ai enfin pris le temps de lire cet article pour comprendre un peu l’opération « SEOFall » dont j’avais notamment entendu parler chez Laurent. Tu touches au génie, là, mec. Je suis 100% d’accord avec toi, ces mecs crawlent comme des porcs, ne respectent même pas les robots.txt, et vendent le résultat de leurs relevés (ce ne sont pas des « analyses ») ultra cher. Bien joué…
Bonjour Nicolas,
Excellente initiative qui devrait faire réfléchir plutôt que râler.
Bien joué comme le dit Didier 😉
Bel exercice de manipulation!
En fait il n’y a même pas besoin de tenter de fausser les statistiques, il y a quelques temps jeromeweb a signalé que pas mal de bots étaient bloqués sur la totalité des serveurs mutualisés 1and1 en France : http://www.jeromeweb.net/serveur/19644-majestic-1and1
Dont Majestic SEO… Entre les robots.txt demandant le blocage des crawlers, les sites mutus 1and1 bloqués et les quelques webmasters comme toi qui dont du cloacking, tous ces outils sont très très loin d’etre précis
Bravo c’est le spam referer du futur 🙂
Sympa ton test qui démontre parfaitement que les outils utilisés ne sont pas toujours si pertinents. Il suffit de faire un rapide comparatif sur le même ndd pour voir que Majestic/ahrefs/Gwt ne montrent pas les mêmes données.
Au vue de certaines réactions on peut se demander si on entre pas dans une période de « méfiance » où la moindre variation non expliquée engendre la panique….